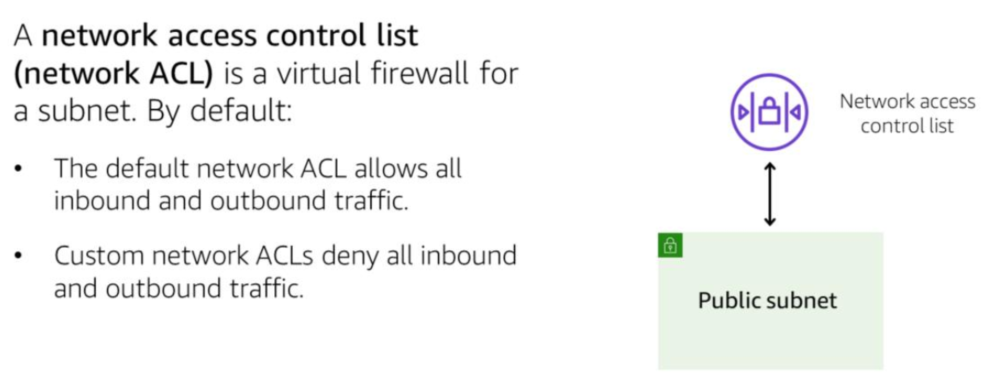
AWS CloudFormation and AWS Serverless Application Model (SAM) are both infrastructure-as-code (IAC) tools provided by AWS for creating and managing AWS resources.
A SAM template is an extension of a CloudFormation template. SAM extends CloudFormation by providing a simplified way of defining the Amazon API Gateway APIs, AWS Lambda functions, and Amazon DynamoDB tables needed by your serverless application. The SAM template is essentially a CloudFormation template with some additional syntax for defining serverless resources.
In other words, a SAM template is a CloudFormation template with additional syntax for defining serverless resources. You can use a CloudFormation template to define any AWS resource, while the SAM template is designed specifically for serverless applications. SAM is a higher-level abstraction for defining serverless applications that makes it easier to create and manage them.
Additionally, when you deploy a SAM template, it is transformed into a CloudFormation template before being deployed to AWS CloudFormation. This transformation is done to ensure that the CloudFormation stack created from the SAM template is compatible with CloudFormation’s API.

You can increase the CPU resources allocated to your AWS Lambda function by adjusting the function’s memory allocation. When you increase the memory allocation for a Lambda function, AWS automatically allocates CPU and other resources in proportion to the memory allocation. This means that if you increase the memory allocation, you will also increase the CPU resources available to the function.
Here’s how you can increase the CPU resources for your Lambda function:
Go to the AWS Lambda console and select the function you want to modify.
Click on the “Configuration” tab.
Scroll down to the “General configuration” section.
Increase the memory allocation for your function.
AWS will automatically allocate CPU resources based on the memory allocation you set.
It’s important to note that increasing the memory allocation for your function will also increase its cost, as you are paying for both the memory and CPU resources. Therefore, you should only increase the memory allocation if your function requires more CPU resources to perform its tasks efficiently.